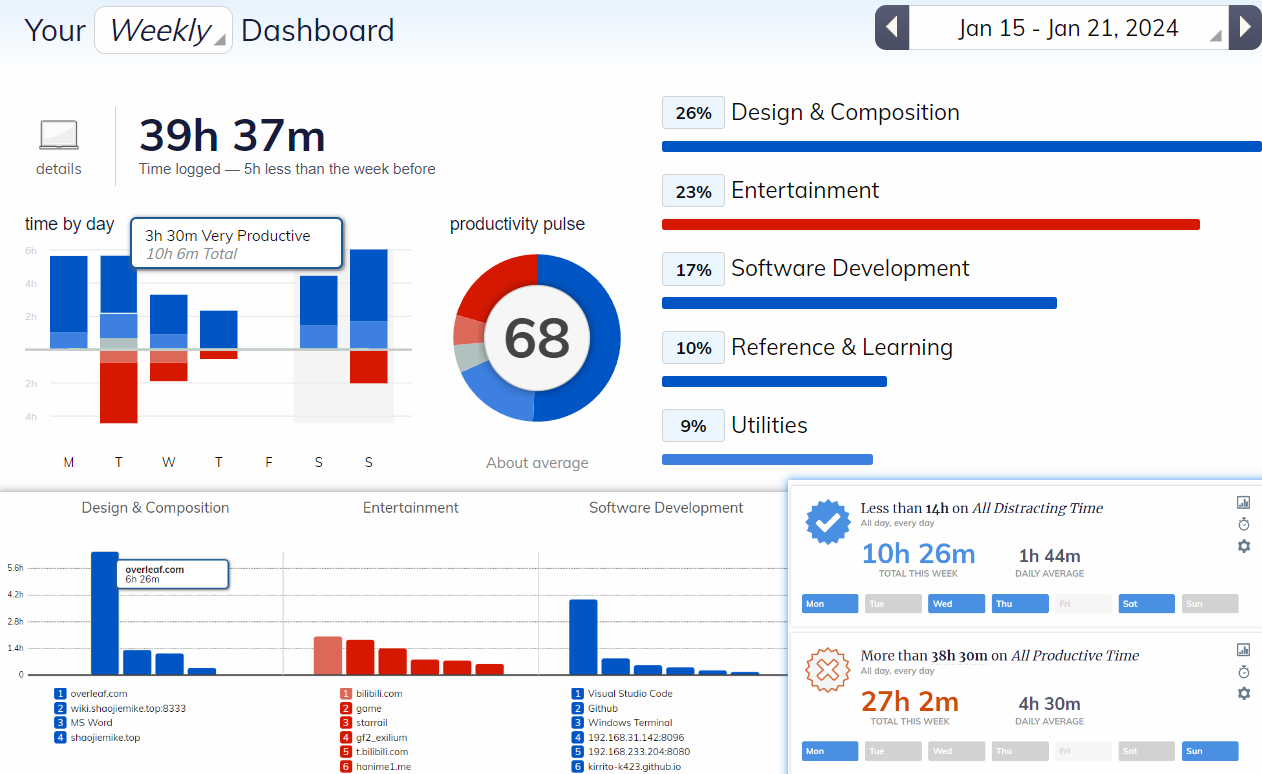
Weekly Summary 6
![]() Jan 21, 2024 12:30 pm UTC+8
Jan 21, 2024 12:30 pm UTC+8
![]() 科大高新区
科大高新区
1 本周的工作
- Mon:
- 和czw讨论a3pim魔改到DFT的可能
- overleaf 草稿到10页
- rescuetime失效了
- Tues:
- overleaf 草稿到15页
- Wed:
- Rescuetime 恢复了,属于记录了,但是没同步显示。
- Baidu 毁约打钱。
- Overleaf: 草稿到20页 Next:吸收uiCA的观点(前端和重命名寄存器),融入到Arm,重点分析与Intel平台的简化区别。
- Thurs:
- Overleaf:方法的表述方式,不要是修bug。高级点,扩展点
- ACSA年会小结
- SAFARI的DATE建议:
- StateOfArt 的比较,难以获得代码 (ideal high-level Comparison, to tell the novelty and difference. And the difference of approach)
- 15到17年很多文章,2017年类似的SC17
- 之前考虑到的缺陷:
- 无法处理 程序输入(Program Input)导致的程序行为特点的变化(load store pressure / Memory access locality)
- SCA缺失对Mem heirarchy的模拟
- 安全的研究,先知道New是什么(比如HMC is new in 2015),再实验。
- 危险的研究: 只是对某个领域感兴趣,但是还不知道不同点在哪里。The question is, are you going to find something different? Those type of projects are quite dangerous, because, you’re you don’t know what you’re going to find, or if you’re going to find anything new. and if you don’t find something new is complicated to sell the paper. 23:44
- 还没看完
- Fri: 不太舒服 chen bai
- Sat: 完成了华为报告内容的填充,达到预估的30页的草稿。下周打算将HPCA和THPC的内容翻译并结合进来,然后将缺失的内容补全并润色逻辑,形成一版合并版的草稿。
- Sun:
| metrics | Monday | Tuesday | Wednesday | Thursday | Friday | Saturday | Sunday |
|---|---|---|---|---|---|---|---|
| Get up | 8:55 | 8:55 | 8:55 | 8:55 | 10:45 | 10:00 | 10:30 |
| Running | x | x | x | x | |||
| In-door Exercise(2~3) | x | x | x | ||||
| Release | xx | xx | x | xx | |||
| Fall Sleep | 3:40 | 4:00 | 2:40 | 4:30 | 4:00 | 3:30 | 3:40 |
| Night Think | |||||||
| Resleep |
- 室内运动: 建议每半天一次(早起和晚归)。内容仰卧起坐(包括侧卧),平板支撑,俯卧撑,Kegel
- 睡觉时间以平板时间为准。
- 打乱作息。
- 思考完后大脑活跃,但是身体已经扛不住了。
- 需要看relax视频,转移大脑注意力
2 下周任务优先级
- 考虑到繁重的任务量,后续有限的两个月围绕毕业论文展开:敲定了更general的题目后,但是当前对于arch64的设计工作过少,支持不起来题目。
- 时间安排:
- 需要在快速填充完论文主体内容(一个月)。 Next:吸收uiCA的观点(前端和重命名寄存器),融入到Arm,重点分析与Intel平台的简化区别。
- 之后着手进一步来提升精度和Arch64的设计,最终画出more accurate by each step的图(一个月)。
- 最后半个月写PPT。准备答辩。
- AI for system 5:调研华为DaVinci架构, 国内架构和NV的区别。阅读更多的基础微信公众号。
- ACSA Lab website(Before 240131): 创建低配版的网站,收集更多人信息,放假前上线(安老师要求)
- 完善问卷:图片要求自行更换背景(或者我手动寻址AI批处理证件照背景,人物位置神色)。论文提供DOI和多媒体链接
- 应该没有时间参与到 Workload Priority的工作里了。
3 AI 相关的拓展阅读
https://github.com/chenzomi12/DeepLearningSystem/blob/main/02Hardware/02ChipBase/05.gpu.pdf
3.1 硬件设计
3.2 AI模型
现在LLM 的大小为什么都设计成6/7B、13B和130B几个档次?解析大模型中的Scaling Law
3.3 瓶颈与性能分析(成本)
Memory Wall in Neural Network Inference
mike: https://le.qun.ch/en/blog/2023/05/13/transformer-batching/
mike: Dissecting Batching Effects in GPT Inference 一个blog你们可能会感兴趣,有GPT inference的内存墙分析
mike: https://www.databricks.com/blog/llm-inference-performance-engineering-best-practices
3.4 国内产品的硬件差距
- 国产GPU新势力摩尔线程
- 国产GPU,可堪大用吗?系列之二:神秘的910B
- 英伟达 vs. 华为海思:GPU性能一览 昇腾910B 达芬奇 gpuScratchpad 思元690 深水4号
3.5 国外先进制程
拆掉英伟达护城河,细节曝光!世界最快超算用3072块AMD GPU训完超万亿参数LLM
3.6 任务评估与时间分配
| 紧急性(3) | 重要性(3) | 喜好(1) | 工作量(3) | 总分 | 分配 | 要求 | |
|---|---|---|---|---|---|---|---|
| thesis | 3 | 3 | 0 | 3 | 9 | 三天多 | 3 |
| AI | 1 | 2 | 1 | 2 | 6 | 两天欠 | 1 |
| Worload | 1 | 1 | 1 | 1 | 4 | 一天多 | 1 |
| web | 1 | 0 | 0 | 1 | 2 | 一天欠 | 1 |
| Summary | 21 |
- 虽然可能会陷入上下午切换导致的效率损失。
- 但是不同于CPU,人脑可以在多进程之间提取通用的思想,融会贯通。
- 另一个好处是,任务开展后才能知道其中的难点,和大约耗时,才有助于实时调整策略应对。不会导致措手不及的狼狈下场。
3.7 工作内容
- 算子底层npu异常检测,内存踩踏,越界。
- 高层模型层级,提高精度,算法强相关。
- (传统内容的创新)基于性能建模,推理和训练加速。
3.8 团队
- 百度编译器 晓光
- 10几个人,后端上海,前端北京。
- 尖酸小黄鸭:T9 - 半年
- T5 -清华的硕士:AI编译器前端,OP → 机器码→kernel。循环融合。
3.9 工作内容
- 鲁棒性(容忍输入扰动的稳定性,处理出错情况的可靠性),正确性,AI原生的思维。
- 后端 code阵列,
3.9.1 AI 编译器
- 中间理论:代数结构,形式化下来。多个op循环融合,map ADT(Abstract Data Type",即抽象数据类型?)
- TVM autotune op规则
- torch 负优化 - 形式化定义,算子以及约束。 A B op融合
Dear Qingcai,
I’m writing to provide an update on my activities from the past week and my plans for the coming week.
This past week, my focus was primarily on my Graduation Thesis. I incorporated content from Huawei’s technical reports to enrich my thesis, reaching an approximate draft of 30 pages. For the upcoming week, I plan to translate and integrate content from two English papers, HPCA and THPC, into my thesis. This will involve filling in missing content and refining the logic to form a consolidated draft. Additionally, I’m considering the possibility of further extending the uiCA details to AArch64.
In parallel, for the AI for System 5 project, I conducted a comparative study of various GPU models and specifications from Huawei and NVIDIA. My research will continue next week, focusing specifically on Huawei’s DaVinci architecture.
Regarding the ACSA Lab website, I’m planning some adjustments and will send out a survey on Monday to gather more information.
Please let me know if there are any changes or additional instructions needed.
Best regards,
Shaojie Tan